
Analyzing and Filtering Data with Apache Spark
- Harini Mallawaarachchi
- Jul 11, 2023
- 2 min read

Apache Spark is a powerful distributed computing framework that enables high-speed processing of large-scale data sets. In this blog post, we will explore how to use Spark's RDD (Resilient Distributed Dataset) to analyze and filter data.
Setting Up the Data
To begin, let's create a simple Scala code snippet that sets up our data:
val data = Array(
"Hi",
"test12345",
"test12",
"Bye"
)
val dataRDD = sc.parallelize(data)
In this code, we have an array called data containing a few string values. We then parallelize the array using Spark's sc.parallelize() method, which converts it into an RDD (dataRDD).
Filtering Data by Length
Now that we have our data ready, let's filter it based on the length of each string. We'll create a new RDD called filterRDD that only contains strings with a length greater than 5:
val filterRDD = dataRDD.filter(line => line.length > 5)
Here, we use the filter() method on the RDD dataRDD and provide a filtering condition as a lambda function. The lambda function checks if the length of each line is greater than 5. The resulting RDD is stored in filterRDD.
Collecting and Viewing the Filtered Data
After filtering the data, we can collect the filtered elements into an array and view the results:
filterRDD.collect()
The collect() method retrieves all the elements from the RDD and returns them as an array. In our case, the filtered data will be printed as follows:
Array(test12345, test12)
The array contains the strings "test12345" and "test12" since they are the only ones that satisfy the filtering condition.
Additional Filtering Example
To demonstrate how filtering works, let's modify the filtering condition and see the outcome. We'll create another RDD called filterRDD that only contains strings with a length greater than 15:
val filterRDD = dataRDD.filter(line => line.length > 5)
In this case, the filtering condition checks if the length of each line is greater than 15. When we collect the filtered data using filterRDD.collect(), we'll get an empty array:
Array()
Since none of the strings in the data array have a length greater than 15, the resulting array is empty.
In Apache Spark, the job window refers to the period of time during which a set of tasks, known as a job, is executed. It represents the duration from when the job is submitted to when it completes or fails. The concept of the job window is closely related to Spark's scheduling and execution model.
When a job is submitted to Spark, it is divided into multiple stages, with each stage containing a set of tasks. These tasks are then scheduled and executed across the nodes in the Spark cluster. The job window encompasses the time taken to complete all the tasks within the job, including the time required for task scheduling, data shuffling, computation, and any necessary data exchange between stages.
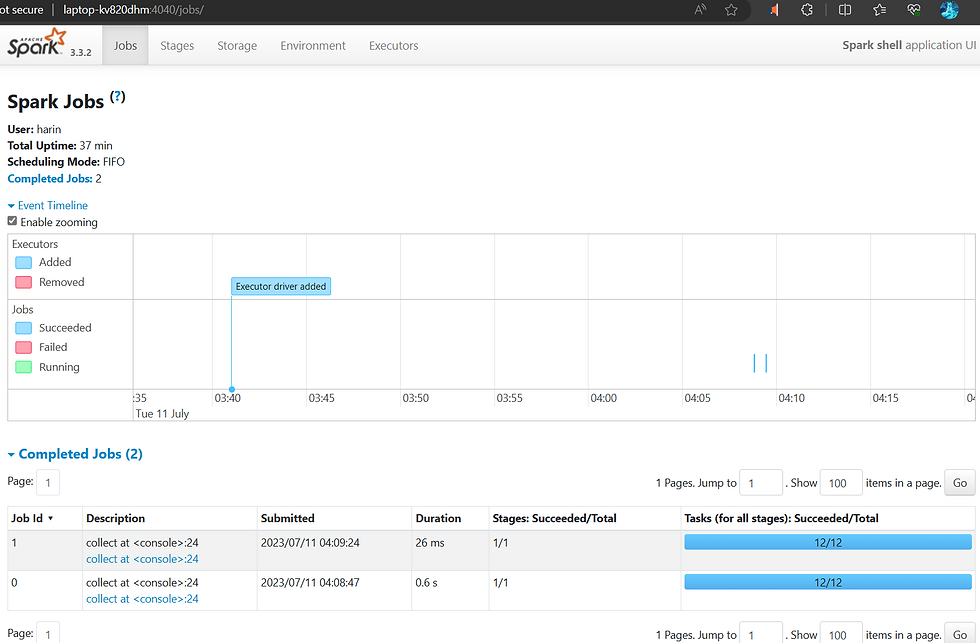
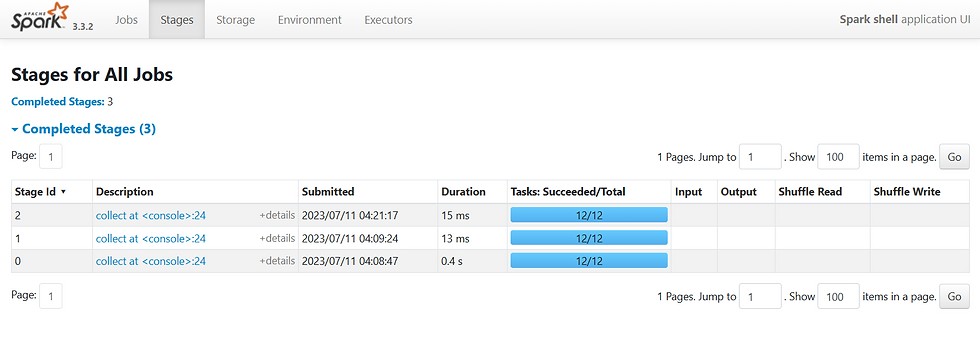
Conclusion
In this blog post, we explored how to analyze and filter data using Apache Spark's RDDs. We started by setting up our data and then proceeded to filter the data based on string length. We learned how to collect and view the filtered results using the collect() method. Finally, we saw an additional filtering example that resulted in an empty array.
Apache Spark's RDDs provide a flexible and scalable way to perform data analysis and processing tasks. By leveraging the power of distributed computing, Spark enables us to handle large-scale data sets efficiently.

Comments