
Getting Started with Apache Spark: Building a Line Count Application in python
- Harini Mallawaarachchi
- Jul 11, 2023
- 2 min read


Project: Line Count
Objective: Count the occurrence of each word in a text document using Apache Spark.
Steps:
Set up Apache Spark: Make sure you have Apache Spark installed and configured on your system.
Create a text file: Create a text file (e.g., input.txt) and add some sample text to it. For example:
Hello, how are you?
I'm doing great, thank you.
How about you?Create a Spark application: Create a new Python script (e.g., word_count.py) and import the necessary Spark modules:
from pyspark import SparkConf, SparkContextConfigure Spark: Set up the Spark configuration and create a SparkContext object:
conf = SparkConf().setAppName("WordCount")
sc = SparkContext(conf=conf)Read the input file: Use the SparkContext to read the input file into an RDD (Resilient Distributed Dataset):
lines = sc.textFile("input.txt")
Perform line count:
text_lines = lines.collect()
counter = 0
for line in text_lines:
counter += 1
Display the results: Print the word count results:
print("Number of lines:", counter)
Stop Spark: Stop the SparkContext:
sc.stop()
Here's how the complete word_count.py script would look like:
from pyspark import SparkConf, SparkContext
# Set up the Spark configuration
conf = SparkConf().setAppName("WordCount")
sc = SparkContext(conf=conf)
# Read the input file
lines = sc.textFile("input.txt")
# Perform word count
text_lines = lines.collect()
counter = 0
for line in text_lines:
counter += 1
# Display the results
print("Number of lines:", counter)
# Stop Spark
sc.stop()Run in CMD:
Run the application: Save the script and run it using the spark-submit command:
spark-submit word_count.py
Check the output: After running the application, you should see the word count results printed to the console:
Number of lines: 3In addition by adding the below lines, it'll save the result in a new file.
# Save in a file
with open("output.txt", "w") as file:
file.write(str(counter))Run in Spark Shell
It can be directly run in the spark-shell as below.
scala> val textLines = sc.textFile("input.txt")
textLines: org.apache.spark.rdd.RDD[String] = input.txt MapPartitionsRDD[1] at textFile at <console>:25
scala> val textLinesList = textLines.collect()
textLinesList: Array[String] = Array(Hello, how are you?, I'm doing great, thank you., How about you?)
scala> var counter = 0
counter: Int = 0
scala> for (line <- textLinesList) {
| counter += 1
| }
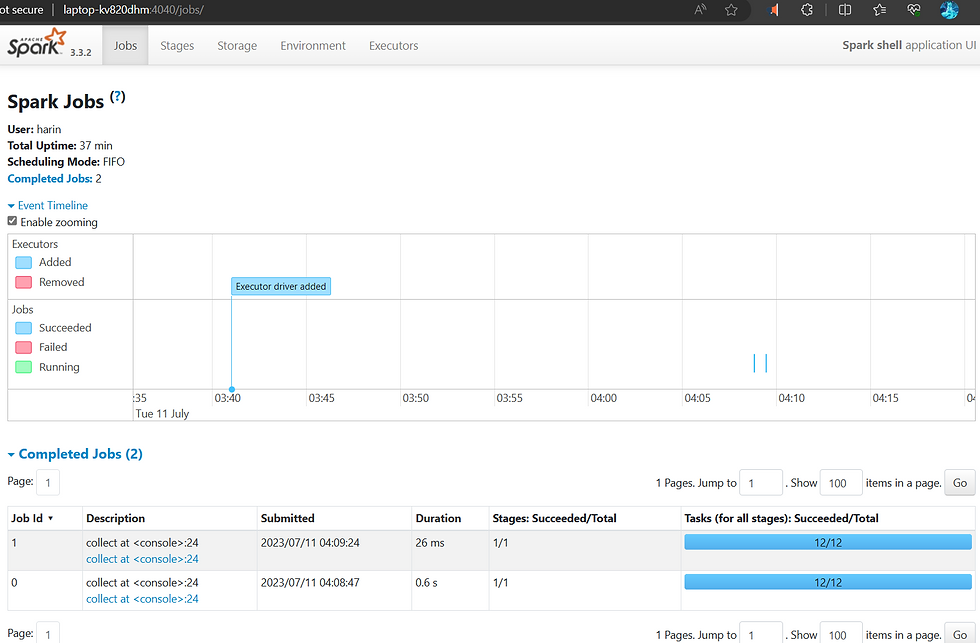
scala> println("Number of lines: " + counter)The Spark jobs can be monitored in the spark-shell application UI

That's it! You have successfully implemented a simple word count project using Apache Spark. This example gives you a basic understanding of how to use Spark's core functionality to process and analyze data in a distributed manner.
Comments